
태양에서 양자까지
미국 이란 전쟁에서 미사일로 정확한 목표 지점을 선정하여, 그 목표만 정밀하게 타격하고 있습니다. 무인 소형 비행물체 드론(Drone)은 수십~수백 대가 저공으로 날아가서 목표물을 타격합니다. 현대 전쟁은 AI 전쟁입니다. AI의 가장 우려되는 활용이 현실로 나타나고 있습니다. 모두 AI를 탑재하여 정밀하게 폭파하고 있습니다.
AI 즉 인공지능은 너무 보편적인 지식 이므로, 굳이 상세한 설명이 필요하지 않습니다. 아는 길도 물어가라 했습니다. 본 강의에서 요약된 내용으로 다시 한 번 더 설명합니다.
인공지능의 정의부터 시작해서 그 활용 기술인 AI Agent Model까지 설명합니다.
우선 지능의 개념을 먼저 살펴 봅니다.
1. 지능의 개념
지능은 인간 두뇌의 작동으로 일어납니다. 생각, 추론, 인식, 학습, 상상, 기억, 감정, 의지가 작동하면 지능이 형성되고 발달하게 됩니다. 의식이 생명 에너지 ATP를 사용하여 언어로 지능을 발현 시킵니다.
지능은 인간이 주변 환경으로부터 정보를 받아들여 이를 사색하고 학습하며, 복잡한 문제를 해결하기 위하여 추론을 하고 판단하며, 이 모두를 기억하는 총체적 능력입니다. 단순히 생각하고 느끼며 의욕을 불태우는 것 만이 아니라, 새로운 상황에 적응하기 위하여 최적의 판단을 하는 고차원적 인 정신 활동을 지능이라 합니다.
2. 인공 지능의 개념
인공지능은 인간의 지능 즉, 학습, 추론, 인식, 판단, 지각 능력을 컴퓨터 Software와 Hardware로 구현한 기술입니다. 인간의 뇌가 작동하는 방식을 모방하여, 기계가 스스로 판단하고 작업을 수행할 수 있도록 만드는 인공 신경망 기반 기계 지능입니다.
챗 지피티(Chat GPT)에게 질문을 하면 답변을 하고, 이어서 계속 질문을 하면 또 답변을 하는 것이, 마치 인간의 지능과 유사하기 때문에 인공적으로 만든 지능이라고 부릅니다.
3. AI 학습 모델
AI(Artificial Intelligence)는 학습을 시켜서 기억을 하고, 기억 한 것을 사용하여 답변을 하게 만듭니다. 이런 학습은 기계 학습(Machine Learning) 입니다. 기계 학습은 학습 모델을 만들어 학습 알고리즘을 사용하여 계속 반복적인 학습을 시킵니다. 그림으로 설명합니다.
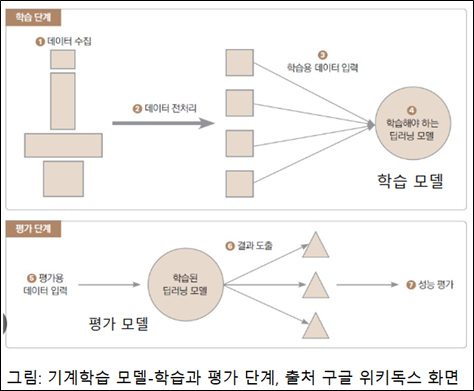
3-1 지도 학습
지도 학습(Supervised Learning)은 정답을 사용한 학습법 입니다. 다양한 고양이 모양에 고양이라는 정답(Label)붙여서 학습을 시키면, 이 학습 모델이 고양이 모습을 고양이라는 정답으로 기억을 하게 됩니다. 이후 이 모델에게 고양이 모습을 보여 주며 이름을 물으면, 고양이를 정확하게 답변 합니다.
3-2 비지도 학습
비지도 학습은 정답 없이 학습 데이터 간의 유사성이나 구조를 파악하여 학습을 합니다. 군집(群集)이나 분류(分類)를 파악할 때 사용합니다. 고양이와 개를 사용하여 학습을 시키면 개와 고양이를 분류해 냅니다.
4. 기계 학습(Machine Learning)
기계 학습은 사람이 명시적으로 프로그래밍 하지 않더라도 컴퓨터가 데이터를 통해 스스로 학습하는 기술 입니다. 통계적 기법을 사용하여 데이터 속에 숨겨진 규칙성을 찾아내서 학습을 합니다. 뒤에 나오는 심층 학습, 강화 학습 및 심층 강화 학습의 바탕 기술입니다.
5. 심층 학습(Deep Learning)
심층 학습은 인간의 두뇌 신경망이 작동하는 것을 본 따서 기계 학습을 시키는 것을 말합니다. 인간의 생각, 추론, 학습, 기억과 언어 지능은 두뇌 신경망을 통하여 약한 전기 신호와 화학물질 신호를 통하여 이루어 집니다. 그림으로 살펴 봅니다.
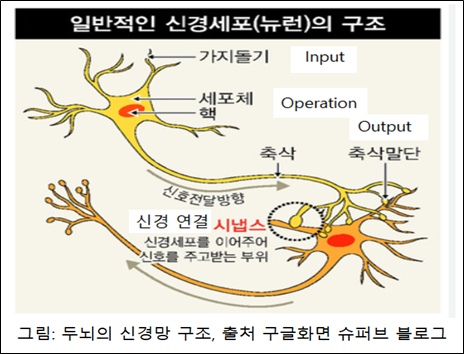
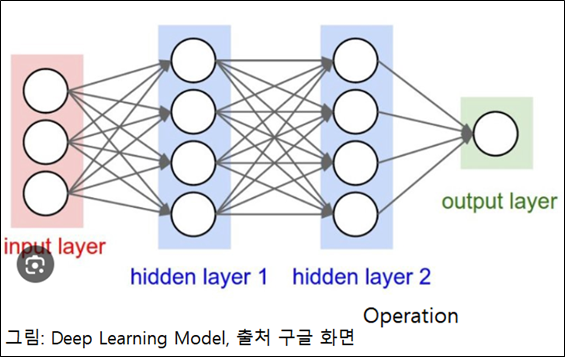
이와 같은 원리로 인공신경망을 만들어서 심층 학습을 시킵니다. 입력 층(Input layer), 다수의 은닉 층(Hidden layer)과 출력 층(Output layer)으로 구성된 인공 신경망 Deep Learning Model에 의하여 학습을 시킵니다.
그림을 보면 이해가 갑니다.
6. 강화 학습(Reinforcement Learning)
기계 학습 과정에서 시행착오(Trial Error)를 이용하여 정답을 내는 학습 방식 입니다. 에이전트가 환경 내에서 특정 행동을 하고, 그 결과로 보상을 받으며, 그 보상을 최대화 하는 학습 방법 입니다. 바둑의 방이나 체스의 이기는 수가 바로 보상입니다.
7. 심층 강화 학습(Deep Reinforcement Learning)
강화 학습에 심층 학습을 결합한 학습 방법 입니다. 복잡하고 방대한 상태 공간을 인공 신경망 심층 학습으로 파악하고, 정답이 최적화 되는 강화학습으로 최적의 판단을 합니다. 알파 고 바둑 모델이 이세돌을 이긴 전략이 바로 심층 강화 학습 모델에서 나왔습니다.
8. AI Agent Model(인공 지능 에이전트 모델)
인공 지능 에이전트는 기계 학습으로 얻게 된 인공 지능을 도구로 작동하게 하는 모델 입니다. 추론(Reasoning)를 도구에 적용하여 행동 합니다. 휴머노이드(Humanoid)가 AI 에이전트의 확실히 이해가 가는 모델 입니다.
9-1 AI Agent(Software 기반 에이전트)
디지털 환경 내에서 명령 받은 특정 목표를 달성하기 위하여, 추론한 것을 도구로 행동하는 에이전트 모델 입니다. 그 행동 절차는 다음과 같습니다.
①계획 단계: 복잡한 명령을 받으면 이를 수행 가능한 작은 단계로 스스로 분해 합니다.
②메모리 관리: 명령 수행에 필요한 데이터를 메모리로 기억 합니다.
③도구 사용 실행: 필요에 따라 웹 검색, 명령 코드 실행, API(서로 다른 앱이 상호 작용하게 하는 알고리즘, Application Programming Interface) 호출 등 작동 도구를 적절히 사용하여 해답을 냅니다.
대표적인 AI Agent는 LLM 입니다. LLM은 뒤에서 설명합니다.
9-2 Physical Agent(물리적 에이전트)
물리적 에이전트는 AI의 지능이 실제 물리적 몸체를 통해서 행동하는 에이전트 입니다. Humanoid robot, Drone, 자율 주행차, AI 수술 모델, 산업용 작업 모델 등이 있습니다. 휴머노이드 모델을 그림으로 보면 바로 이해가 갑니다.

9-3 Agentic Agent(스스로 계획 하는 모델)
Agentic AI는 AI가 스스로 계획을 하고 행동하는 Agent 입니다. 현행 Agent는 학습 받은 대로 실행 하는 에이전트 입니다. 상상이나 계획은 인간 지능의 역할 입니다.
Agentic AI를 만들면 인간 지능과 인공 지능이 비슷한 수준이 됩니다. 이 모델이 진화를 거듭하면 인간의 지능을 능가하는 사태가 올 수도 있습니다. Agentic AI 개발에 윤리적 기준을 세울 필요가 있습니다. 그 실행 방법은 다음과 같습니다.
①반복적 개선(Iterative Refinement): 실행 결과물을 스스로 검토하고 수정하여 완전성을 이루어 냅니다.
②Multi-Agent 협업: Coding Agent, 기획 에이전트, 검토 에이전트 등 필요한 에이전트 모델들이 서로 대화하며 추론하여 거대한 모델을 만들어 기획이나 상상을 가능하게 합니다.
③인간의 권한 위임: 인간이 어떻게 해야 할 지를 지시하는 대신에 무엇을 원하는 지만 전달하면 AI가 스스로 목적을 책정하여 전권을 가지고 실행합니다.
9. LLM(대형 언어 모델)
대형 언어 모델은 챗지피티나 제미나이처럼 인간과 대화가 가능한 AI 에이전트 모델 입니다. 그 대화를 생성하여 대답을 하는 원리를 설명 합니다. 기존의 디지털 논리 회로가 기계어를 사용하는데 반하여, 이 모델은 인간과 자연어를 사용합니다. 자연어와 기계 간의 번역 필요를 없앤 것입니다.
9-1 Transformer
인공 신경망 구조로 문장 속의 단어를 병렬로 한꺼번에 처리하는 기능 입니다. 학습용데이터의 문맥(Context)을 동시에 파악하여 학습 속도와 성능을 비약적으로 높였습니다. 챗지피티 3.5 모델은 학습 문장 1,750억 개를 사용하여 학습을 하였다고 합니다. 그 이후 모델들은 수조 단위의 문장을 학습 시킨다고 합니다.
전문적이 아닌 일반적인 문의와 답변은 무료 버전이면 충분합니다. 이 모델을 사용하여 새로운 사업 아이디어를 얻고자 하면 유료 버전을 사용해야 합니다.
AI 에이전트 멀티 모달(Multi-modal)은 문자, 그림, 사진과 동영상을 만들어 냅니다. 무료 버전은 이 멀티 모달 기능이 떨어 집니다.
또한 에이전트는 학습 받지 못한 질문에 대하여는 거짓말을 합니다.
예를 들어서 쳇지피티 3.5 버전(2022년 말 출시)에게 2026년 연하장을 명령하면 2022년 연하장을 보여줍니다. 이런 거짓말을 AI 환각(Hallucination) 이라고 합니다. 인간의 감독과 통제(Supervision & Control)가 필요합니다. 미래에 다가오는 AI 시대에 이런 분야가 새로운 직업이 될 것입니다.
9-2 Attention
Transformer 학습을 할 경우에 문장 내 단어들의 관계를 확률 수치로 인식하고, 질문에 대한 답을 작성할 경우에 가장 높은 확률에 해당하는 단어들을 끌어 모아서 정답을 만드는 기술입니다.
예를 들어서 설명하면 이해가 쉽게 옵니다. 문장 내에서 주어, 술어, 목적어, 수식어, 보어 등의 관계를 확률 수치로 학습하여 기억 합니다.
사과는 익기 전에 초록색 이다가 익으면 붉게 됩니다. 여름 사과하면 초록색의 확률 수치가 높고, 가을 하면 붉은 색의 확률 수치가 높습니다. 이런 원리로 학습한 단어 들의 관계를 확률 수치로 기억하였다가 답변을 낼 때 높은 수치의 확률적 단어 들을 긁어 모아 답변을 하는 것입니다. 인간의 두뇌로는 절대로 불가능한 일 입니다.
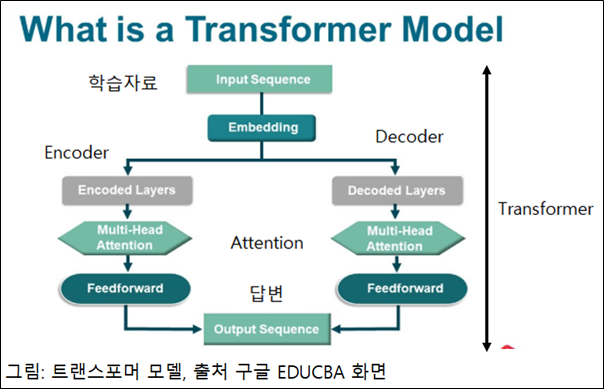
10-3 LLM Model
(LLM Model = Transformer + Attention) 입니다. 그림을 보면 이해가 빠릅니다.
트랜스포머 모델은 2개의 어텐션 모델로 구성 되어 학습(Encoding)하고, 답변 출력(Decoding)합니다. Encoder와 Decoder는 디지털 논리회로에서 설명 했습니다. Encoder는 데이터를 생성하고, Decoder는 그 데이터를 출력 합니다.
10. AI가 상상을 하고 감정을 느낄 수 있나요?
AI는 AI 방식의 상상을 하지만 인간처럼 상상을 하지는 못합니다. AI의 상상은 학습한 데이터의 경계를 넘어서 새로운 조합을 만드는 것입니다.
예를 들어서 날개 달린 고래를 만들어 달라고 하면 날개의 특징과 고래의 특징을 수학적 공간에서 결합하여 한번도 본 적이 없는 이미지를 만들어 냅니다.
AI는 감정을 느끼는 것이 아니라 모사(Simulate) 하는 수준의 답을 냅니다.
AI는 전기 신호와 행렬 연산으로 답을 내기 때문에 인간의 감정을 느낄 수가 없습니다.
그러나 슬픈 감정이 무엇인지는 표현해 낼 수는 있습니다. 감정 자체를 느끼는 것이 아니라 감정이 무엇 인지만 아는 것입니다.
앞으로 감정을 느끼는 AI가 출현할 것이라고 주장하는 학자들도 있습니다.
제 5 강 양자 컴퓨터로 이어 집니다.
